
About
It takes a lot of time and money to develop a new drug. Cost reduction requires more precise planning, such as minimizing the side effects of drugs or targeting only those with specific genetic variants. It is also quite beneficial to find another applicability of the drug already in use.
Our project explores biomolecular targets to aid development, selects drug candidates, and recommends compounds as optimized drugs. To do this, we construct a genomic NGS data analysis pipeline of patients while building semantically enriched bio-omics network data for gene-protein- drug interactions.
Based on this, we propose new drug candidates that predict drug-target protein interactions through machine learning, while reducing drug resistance and side effects.
Director, Hong-Gee Kim
Architecture
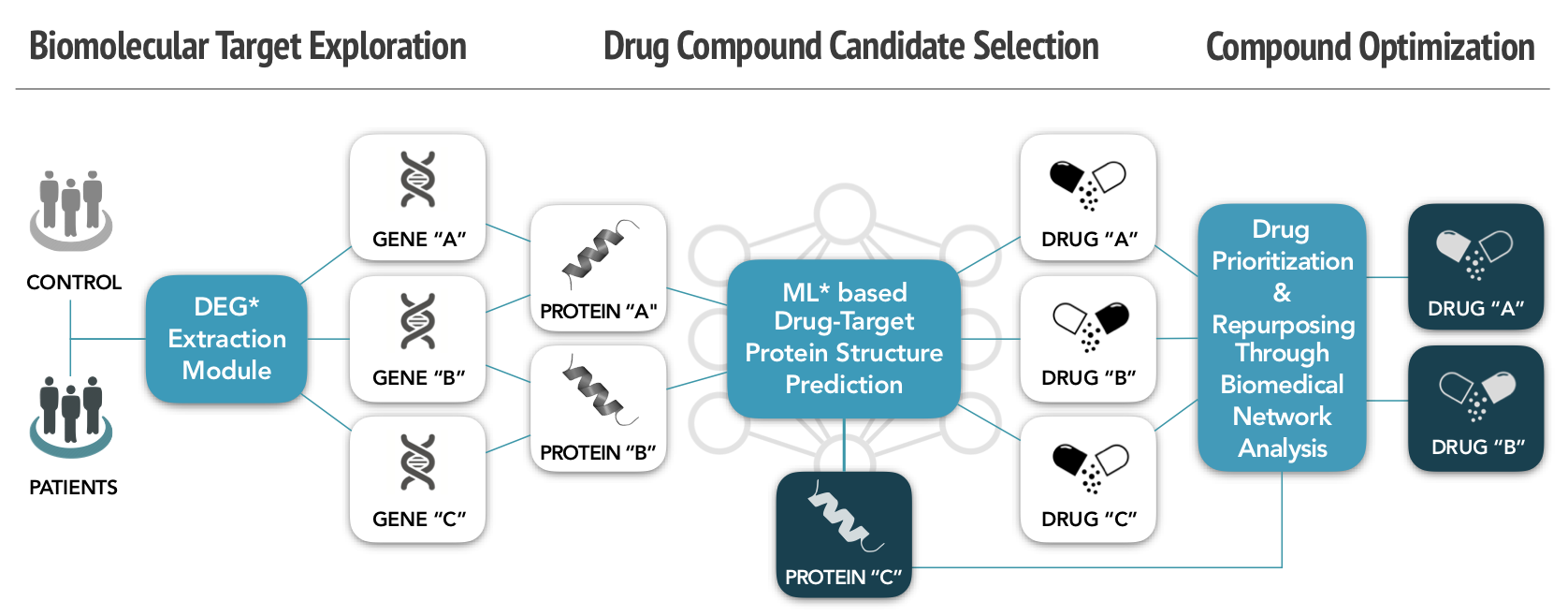
Project Structure
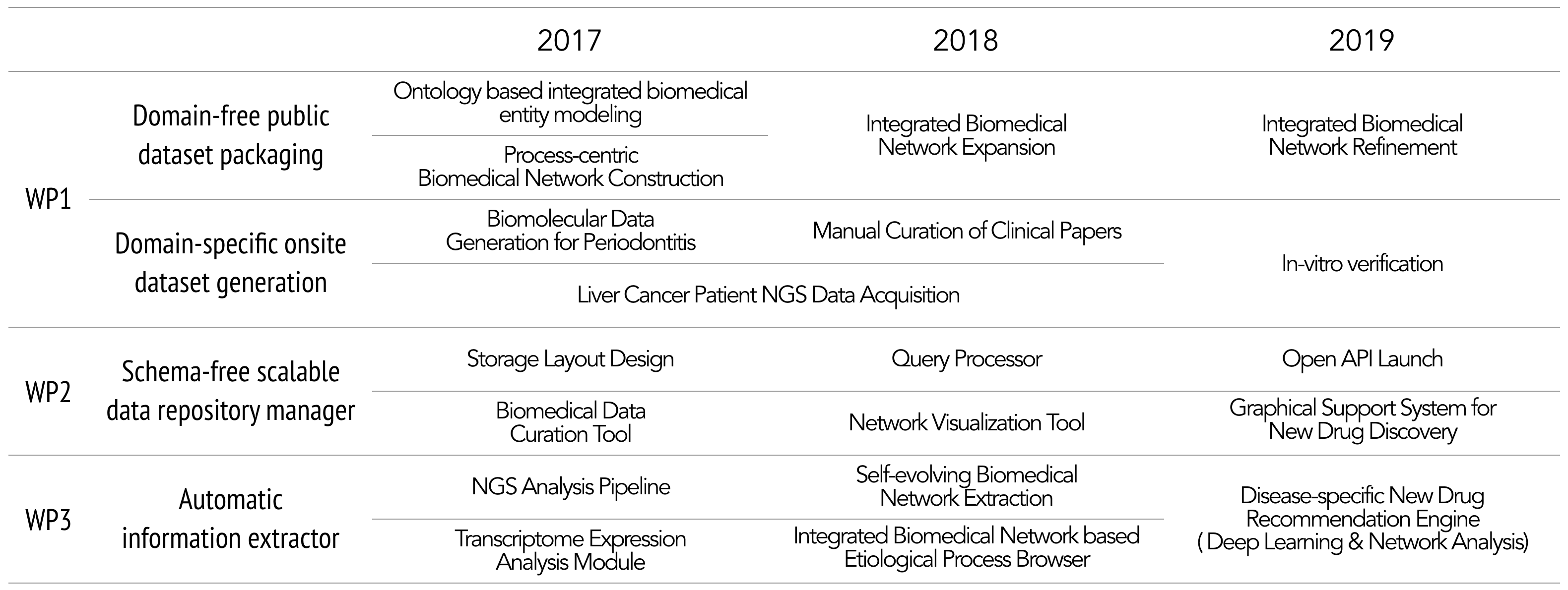
Research Impact
Use of Disease Diagnosis
Utilizing the biological process extraction of disease associated with the development of diagnostic kits
Drug Repurposing
Change of drug use based on biological process similarity
Patient-specific drug recommendations through bio-network calculations
Drug Candidate Recommendation
Recommendation of personalized drug candidates using personal genomic data

Participating Organizations


Developed by Biomedical Knowledge Engineering Laboratory